自己的AI自己”練” :AI TOP設定與介面說明 LLM訓練立即上手
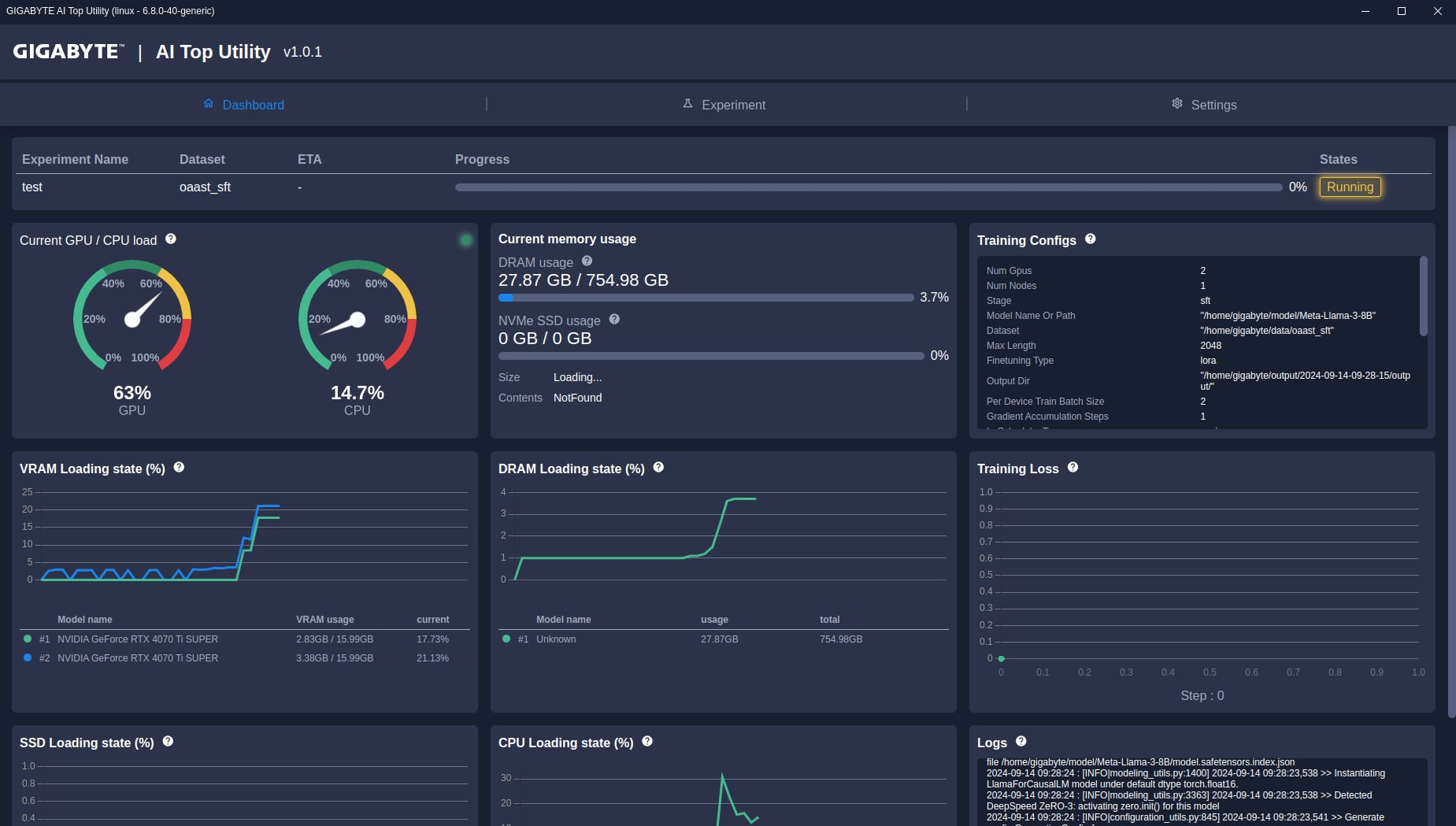
瞭解如何安裝大預言模型LLM之後,就可以開始使用AI TOP應用程式來訓練他們,做出更適合自己使用的私有化AI了。在開始使用之前,有些基本設定及說明要先弄清楚,以便更有效率或更精準的進行相關訓練。
點選AI TOP應用程式的Experiment選項,這邊有一些欄位需要手動選擇,這些選項會依照使用的LLM而有所不同,這邊以通用的規範進行說明,更多細部設定值,請參閱LLM的相關需求。
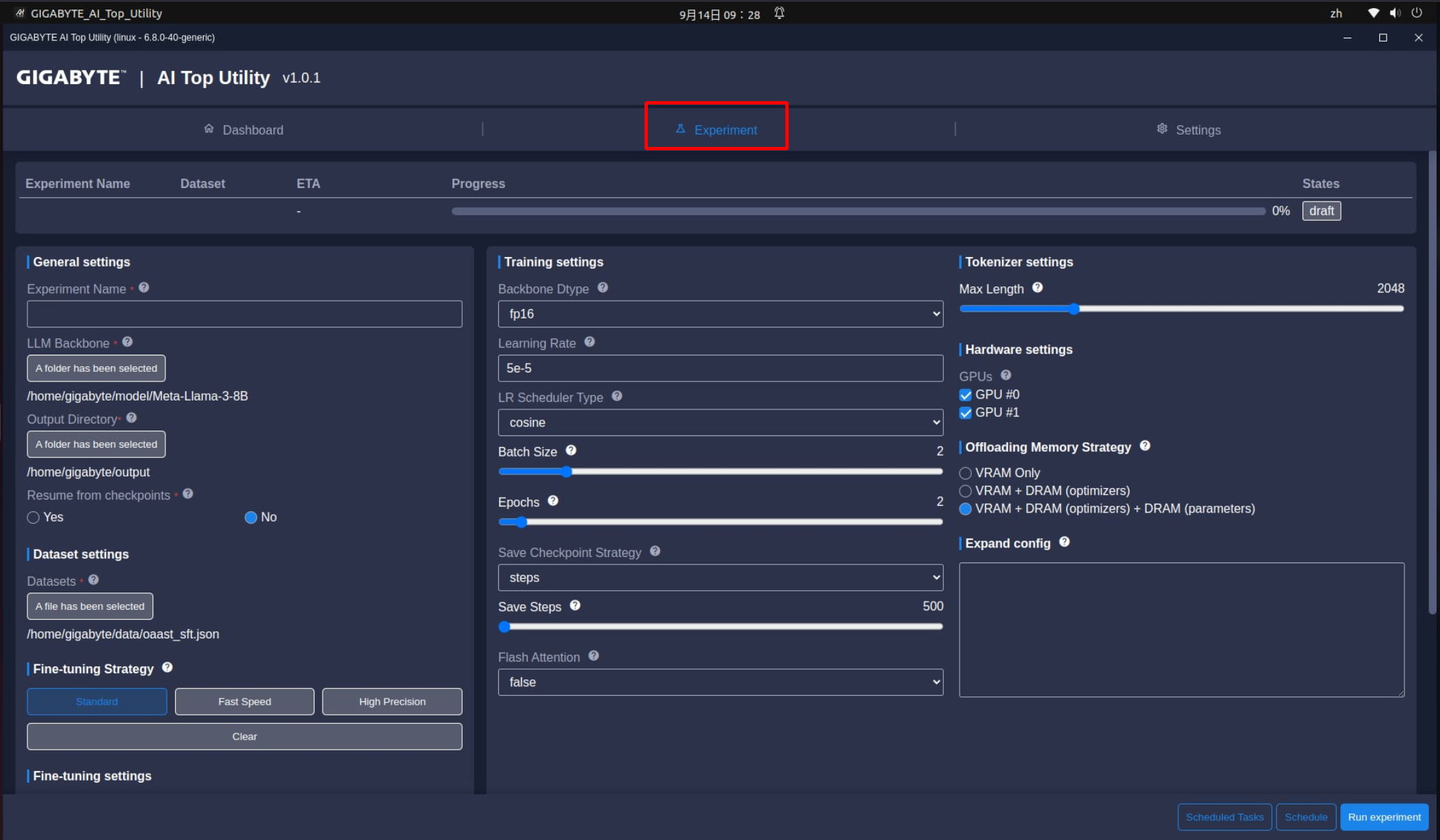
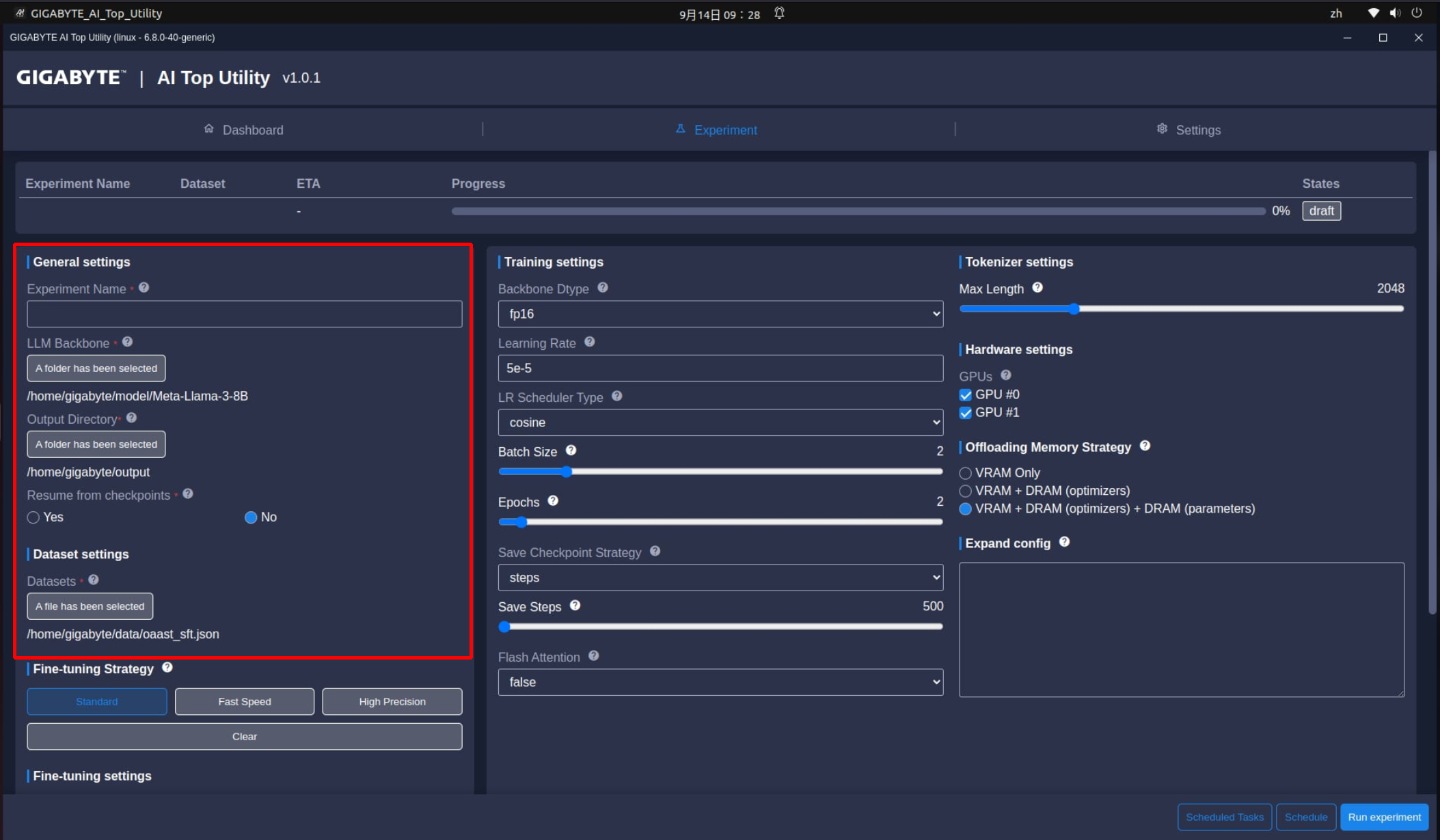
首先是在一般設定(General settings),不管是入門使用者或進階玩家都需要進行下列設定:
- Experiment Name:這是AI訓練的作業名稱,可以視為訓練的檔名,建議可以取一個比較容易識別的名稱,例如:20240901_Meta-Llama-3-8B_Training_001。
- LLM Backbone:這要訓練的大語言模型存放位置,選項下方連結要選擇存放LLM的連結,這個連結就是上一篇文章裡面提到的Model資料夾,通常是/home/主機名稱/model/LLM資料夾名稱。*這邊的主機名稱跟所有LLM資料夾名稱,會依機器設定不同而有差異,要稍微注意一下。
- Output Directory:這是用來儲存LLM訓練結果(如模型權重、日誌和其他輸出資料)的資料夾路徑。通常是/home/主機名稱/output。*這邊的主機名稱也會依機器設定不同而有差異。
- Resume from checkpoint:人生常充滿意外,AI訓練也是。這個功能可以讓訓練從上一個檢查點繼續進行,而不需要從頭開始,以節省訓練的時間。所以開始訓練之後,可以啟用這個功能,以避免不必要的麻煩。
- Datasets:指定在訓練期間用於模型調校的訓練資料檔存放位置。路徑通常是/home/主機名稱/Data/訓練資料檔名稱。*訓練資料檔的支援格式包括txt、csv、json等,相關格式可以在Hugging Face網站找到,但產出有價值的訓練資料檔,是AI訓練最難的部分。
設定完這些選項之後,我們先跳到最右邊的硬體設定這邊Hardware Settings調整一下硬體配置,其中GPUs用指要於訓練過程的顯示卡數量。會自動列出目前系統中所有可用的顯示卡。使用者可以在清單中選取或取消選取要用來訓練LLM模型的顯示卡。而Offloading Memory Strategy則提供多種卸載模型最佳化的設定,並可以選擇套用到系統記憶體或(和)NVMe SSD,以便進行硬體功能最佳化並避免記憶體不足問題。如果要獲得最高效能,可以選到最高設定,當然也會比較耗電,可以依照需求選擇。
做完上面設定之後,基本上就可以開始訓練AI了,看起來很簡單對吧?這就是技嘉對入門使用者的貼心跟開發這些功能的初心,讓初學者不需要受限於程式的能力跟背景就可以使用,更貼心的是AI TOP還提供了簡易的LLM訓練預設模式,提供已經寫好的設定,讓沒有AI相關基礎的使用者,也能輕鬆訓練AI,包括:
- Standard(標準模式):訓練速度跟精準度都中等,產出較平均
- Fast Speed(快速模式):訓練速度最快,但精準度最低,可用於練習
- High Precision(精準模式):準確度最高,訓練最完整,但訓練速度最慢,適合有比較充裕時間的訓練需求。
入門使用者可以依照需求直接選擇上面選項來進行訓練,之後按下Run Experiment就可以了!
更多設定看看這邊
對於想要有更多設定空間的進階AI使用者,可以按一下Clear來停用預設的快速訓練模式,改用手動調整參數,AI TOP提供的訓練的方法,包括:full、freeze、LoRA、qLoRA,每個方法影響訓練記憶體需求和訓練後LLM的品質,其中:
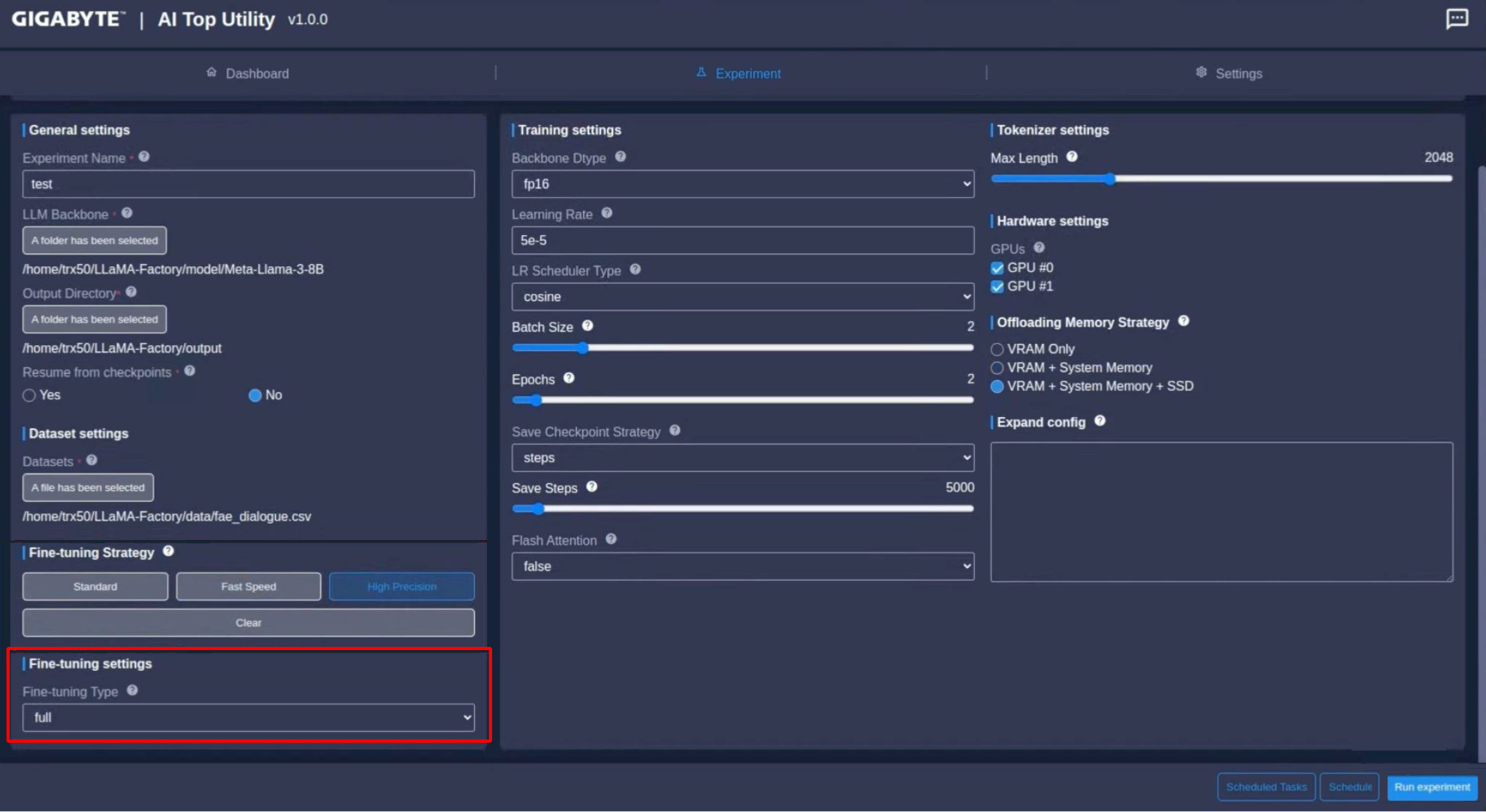
- Full:模型的所有參數在訓練過程中都會更新。這種方法根據新的訓練資料調整模型每一層的權重。
- 優點:模型完全以新資料檔為基準,在特定任務或訓練需求有更好的效果呈現。
- 缺點:全面訓練需要大量的運算資源,如果新資料跟原始資料太相似,可能影響訓練結果。另外還可能發生嚴重失誤,讓模型失去執行最初訓練任務的能力。
- Freeze:模型的某些層在訓練期間的權重不更新,只有某些會根據新資料改變。
- 優點:凍結某些層可以減少計算成本和需要更新的參數數量。也有助於保留模型學到的一般知識,並降低嚴重失誤的風險。
- 缺點:由於只更新了模型的部分參數,因此模型訓練效果可能會比較受限。
- LoRA:透過導入可訓練的低秩矩陣,來修改預先訓練的模型,這些矩陣調整的是模型現有權重,而不是取代它們,可以減少模型參數的數量和運算需求。
- 優點:減少模型訓練時的運算資源需求,可提高訓練效率,並且在保持效能的同時降低模型的複雜度。
- 缺點:在某些情況下,可能無法提供與完全訓練相同的彈性。
- qLoRA:LoRA的量化版本,理論上可以用更少的位元來表示LoRA參數,節省記憶體使用率和效能耗用。
依照不同訓練方式,會有更多進階設定選項,如果選擇Freeze會看到下面選項:
|
Number of Trainable Layers |
用來指定在訓練過程中可以調整的模型層數,選擇層數越高,更新的部分越多,但更耗用系統資源。 |
|
Name Module Trainable |
主要是指選項啟用時可訓練模組或架構的名稱:MLP或Self-Attention等。 |
如果選擇的是LoRA,會有更多選項要設定,包括:
|
LoRA Target |
用來指定LoRA對應目標模型的哪些部分或模組(q_proj, v_proj, k_proj, o_proj)。這些模組的選擇會根據不同LLM而有所不同,請參閱各LLM的需求說明。 |
|
LoRA Rank |
LoRA中使用的矩陣分解維數。LoRA Rank的範圍依據2的n次方(2^n)規則而定,以最佳化神經網路的學習原理。n的範圍包括:[0,2,4,8,16,32,64,128,256…],數字越大維度越多,可調整的自由度也越高。 |
|
LoRA Alpha |
LoRA權重的比例因子。LoRA Alpha的範圍依據2的n次方(2^n)規則而定,以最佳化神經網路的學習原理。n的範圍包括:[0,2,4,8,16,32,64,128,256…],數字越大比例越高,可調整的彈性也越高。 |
|
LoRA dropout |
訓練期間對LoRA權重應用dropout的機率。可設定範圍:[0~1]。 |
|
Quantization Bit |
用來定義模型權重的位元精準度,通常是為了減少模型大小或加速推理速度。用來將模型參數的高精度浮點數(32bits, 16 bits)轉換為低精度數字(8 bits, 4 bits)。可設定數值範圍包括無, 4 bit及8 bit。 |
選擇完訓練方式之後,需要進一步調整Training settings,包括:
- Backbone Dtype:依據LLM不同權重的資料類型,來決定訓練後的模型精準度,可選擇的數值包含fp16, bf16及fp32。
- Learning rate:學習速率是模型在處理每個小批量資料後,更新其權重的速度,資料範圍介於0跟1之間。
- LR Schedule Type:在訓練的過程中調整訓練週期或迭代之間學習速率的策略。設定選項包括Cosine(餘弦)及linear(線性)。
- Batch size:在訓練模型迭代期間,每個GPU中小批量使用的訓練範例數量。這個數值範圍依據2的n次方(2^n)規則而定,以最佳化神經網路的學習原理。n的範圍包括:[0,2,4,8,16,32,64,128,256…],數字越大數量越多。
- Epoch(訓練週期):是將整個訓練資料集完整通過神經網絡一次的過程。每個Epoch包括一次完整的正向傳播和反向傳播。這個過程會重複多次,以便模型能夠學習資料中的模式和特徵。
- Save Checkpoint Strategy:訓練期間所採用的檢查點,選項包:
- None (無):在完成整個訓練過程之前都不儲存檢查點。
- Epochs (週期):每完成一個訓練週期設定一個檢查點。
- Steps (步驟):每n個訓練步驟設定一個檢查點,Save Steps需要設定兩個檢查點之間的更新步驟數值。例如Save Steps = 500表示在訓練過程中每500個訓練步驟就儲存一個檢查點。
- Flash Attention:一種演算法最佳化技術,啟用Flash Attention 2可大幅節省繪圖記憶體使用,並將運作速度提高2~4倍。設定選項包括True(啟用)跟False(不啟用)。
最後幾個選項是Tokenizer settings這邊的Max Length,代表在LLM訓練期間「輸入查詢」和「輸出答案」的最大長度。依照開放AI標準,通常是1000個詞元(Token) ~ 750 個單字。長度範圍包括512, 24以及2048~128k這個範圍,並取決於預訓練的LLM的能力而定。
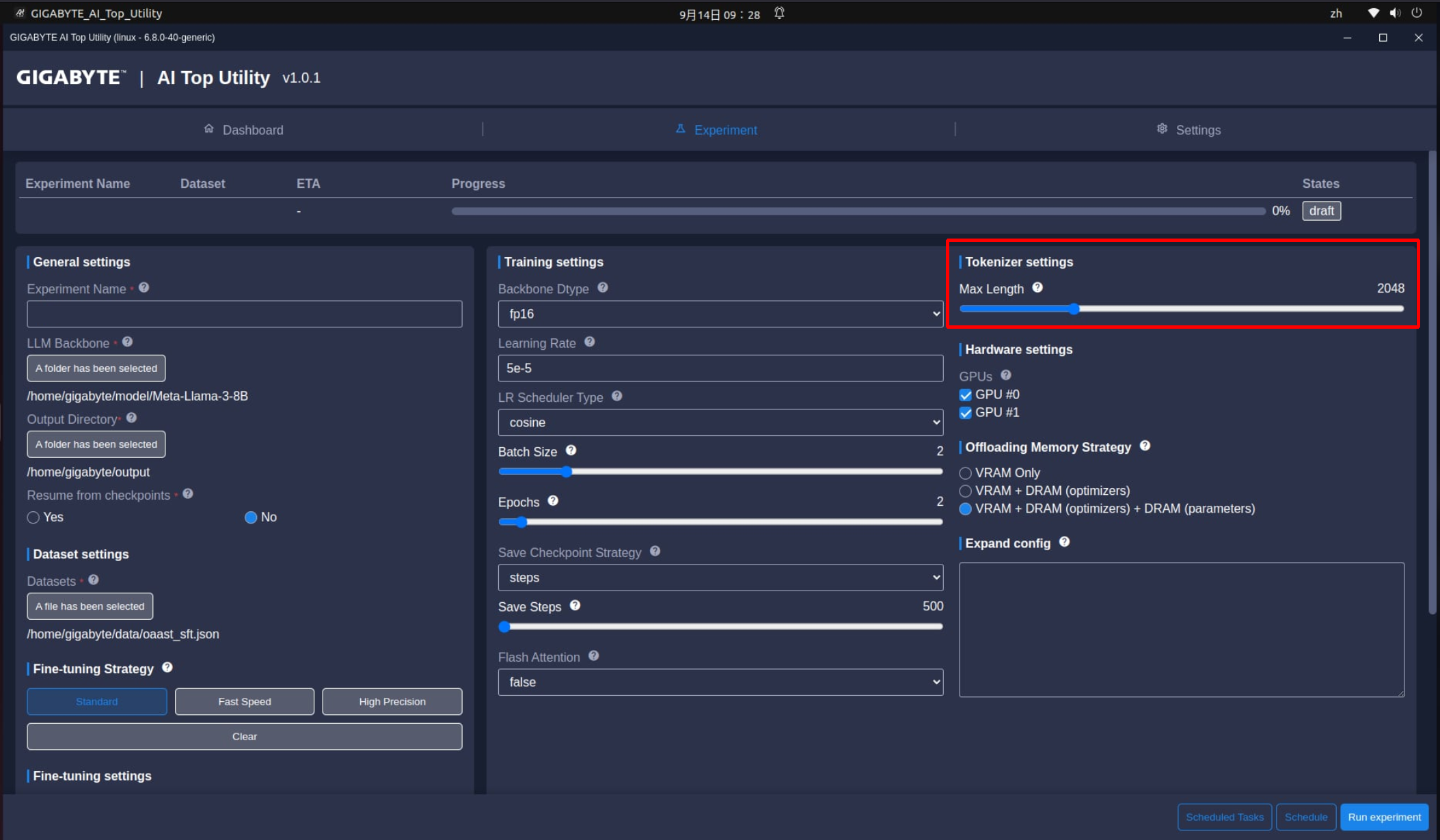
而Expand Config這個技嘉獨家技術,則可以編輯或增加更多訓練指令,讓進階使用者可以依照自己的方式訓練LLM模型。
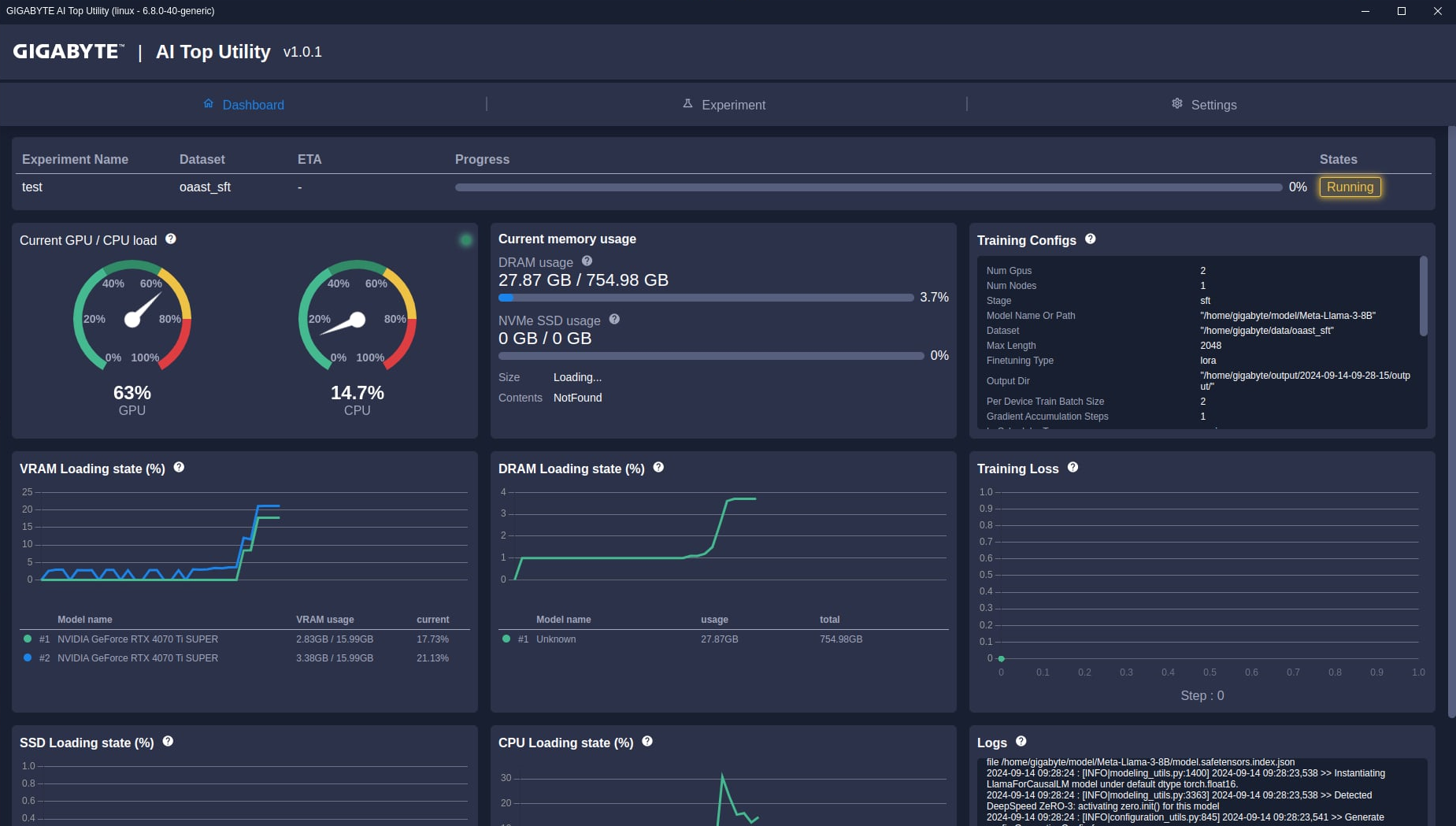
到這邊,所有簡易跟進階設定都已經完成了,不管用的是哪一種,都只要按下Run Experiment就會開始進行LLM訓練。之後回到Dashboard模式,這邊會顯示LLM訓練的進度、所需時間跟所有硬體負載跟運作狀況。如果訓練出現問題,也可以在Logs這邊看到相關訊息,以進行分析。
補充說明:聽說AI很耗電??
是,AI的運算需要運用很多電腦資源,為了讓系統有更足夠的運算能力,需要有足夠的電力作後盾,所以會比一般電腦系統更耗電。
雖然我們無法控制系統用多少電,但至少可以在電費比較便宜的時間進行。例如台灣地區夏月尖峰時間為下午4時到晚上10時,每度電6.92元;半尖峰時間為上午9時到下午4時、晚上10時到12時,每度電4.54元;離峰時間為凌晨12時起到上午9時,每度電1.96元。如果用離峰時間來進行訓練,每度電可以省將近5元。
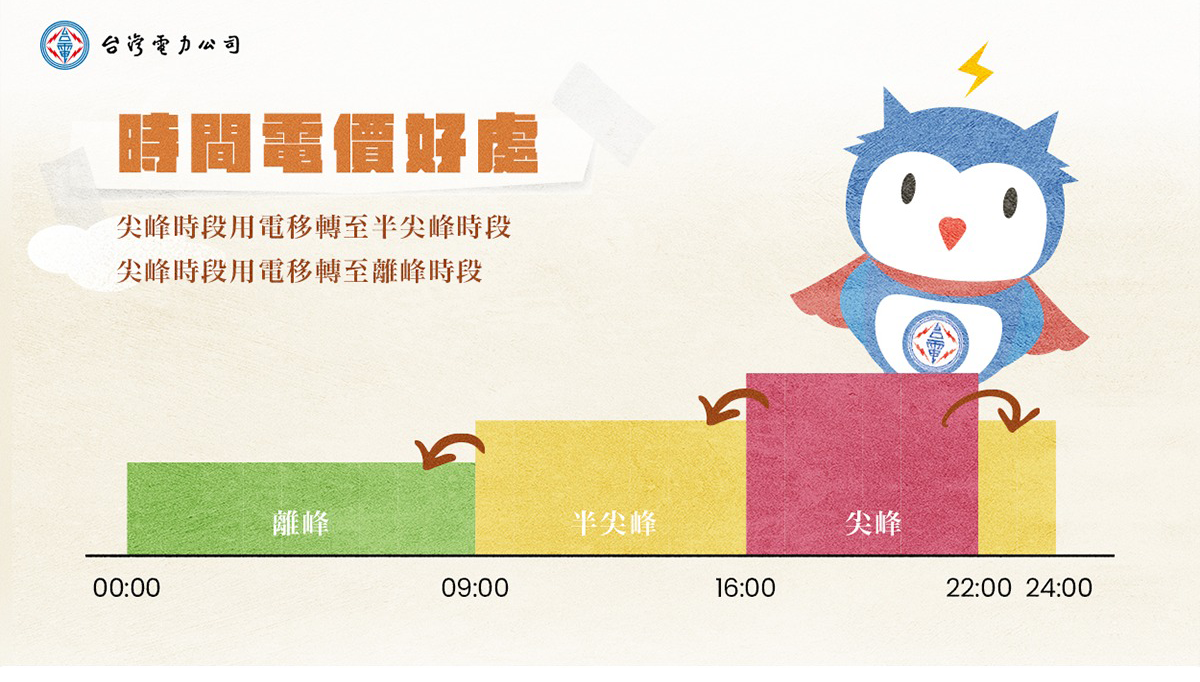
所以AI TOP提供了一個Schedule的功能,可以在這邊設定哪些時間段進行LLM訓練,以節省訓練費用。
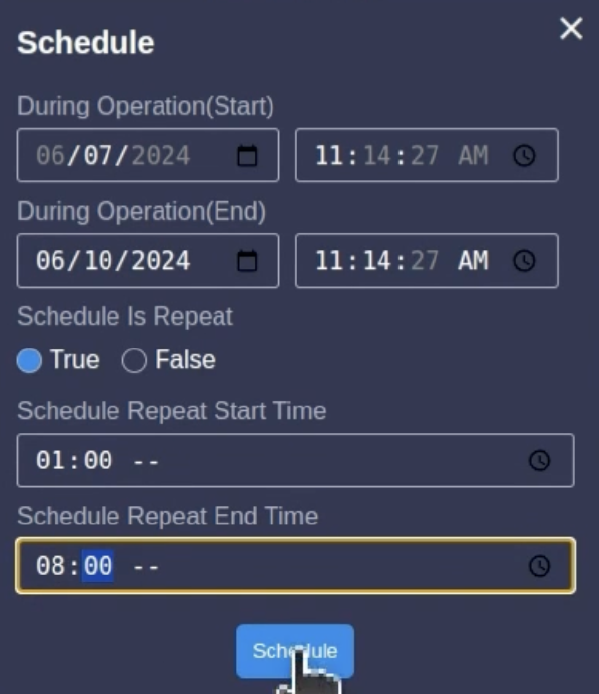
到這邊,AI TOP的相關設定說明已經完成,相信大家跟著這三篇文章的說明,可以對LLM訓練有一些基本概念並可以進行相關運算,也請大家持續關注AORUS TW的社群AORUS台灣社群網站:FB、IG、YT以獲得更多相關資訊。
討論
- NEXT如何選擇筆電的處理器?