自己的AI自己”練” :怎麼安裝大型語言模型LLM

在上一篇文章,我們跟大家說明了如何安裝AI TOP應用程式,接下來我們要開始安裝大型語言模型LLM了!AI TOP可以支援及訓練的語言模型很多,這邊我們列出目前可以支援的類別及種類,同時加上連結,以提供進一步說明,這些LLM都可以在Huggingface 網站找到,並有相關說明,有興趣可以先點選進去看一下,再決定要不要佈置。
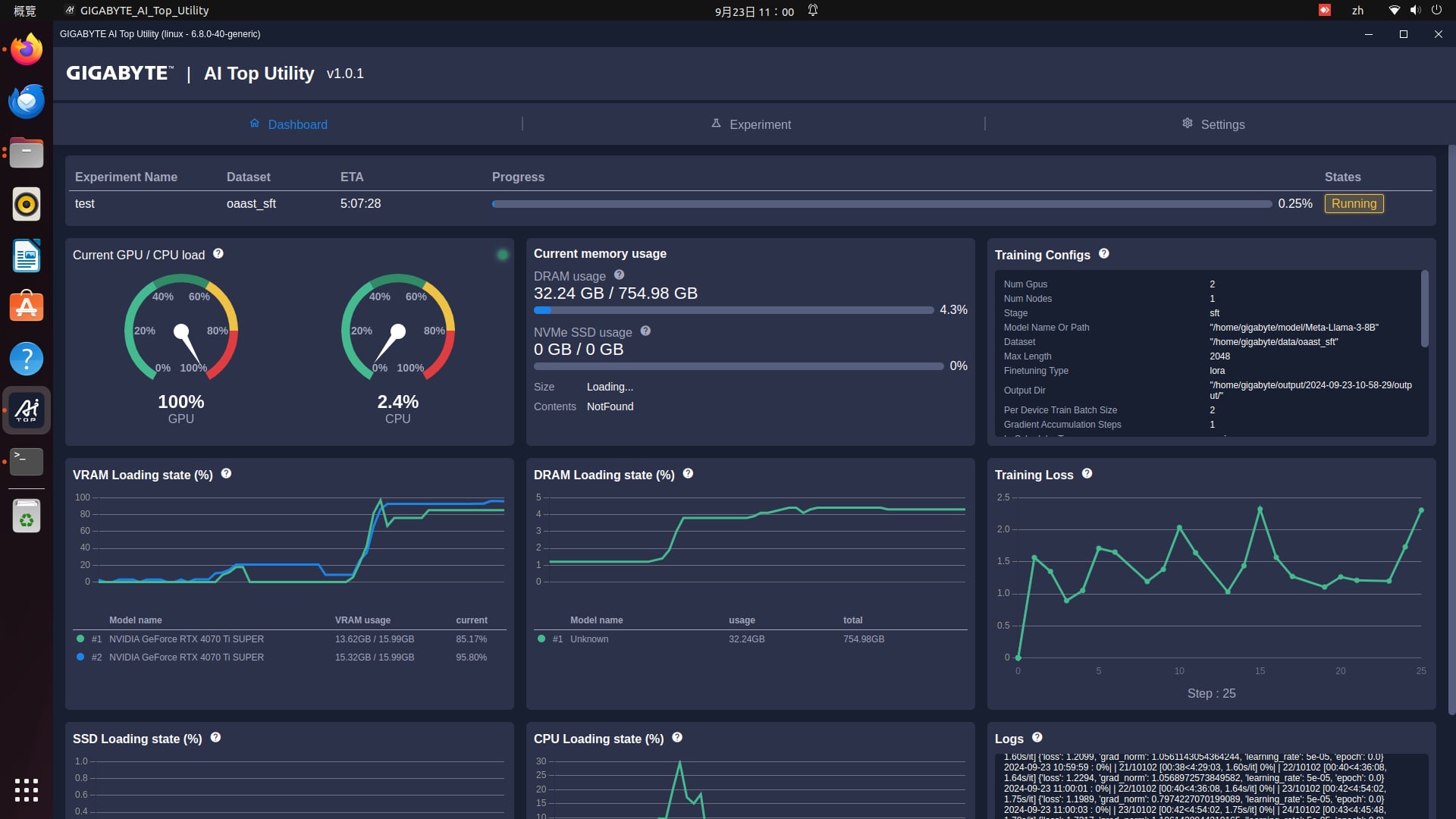
AI TOP應用程式軟體安裝完成後,請在”Home”資料夾中建立三個子資料夾,包括「model」、「data」和「output」等,用來儲存相關資料,其中
「model」資料夾用於存放你所要訓練的LLM主要資料(backbone models.),如上表所列,這些模型可以從 Huggingface 網站下載,或直接點選表中各種LLM的連結取得,之後將它們儲存到「model」資料夾中,以利後續訓練。你也可以依照需求在「model」資料夾裡建立許多子資料夾,存放各種LLM,來進行不同訓練。
選定要使用的LLM之後,接下來請到Huggingface 網站(或直接點選表裡面的連結)您的登入帳號密碼之後,網站會需要進行簡單的驗證。通過驗證之後,就可以直接把LLM的資料下載下來了,以Meta的Llama 3 8B為例,請在「model」資料夾裡建一個「Meta-Llama-3-8B」資料夾,以存放相關檔案。
另一個取得LLM主要資料的方式是,在「model」資料夾中,點選滑鼠右鍵,開啟terminal(終端機),並複製下面字串
pip install huggingface_hub
huggingface-cli login
sudo apt install git-lfs
git clone https://huggingface.co/meta-llama/Meta-Llama-3-8B
這邊一樣是以Meta的Llama 3 8B為例,如果要改用其他LLM,例如Baichuan2-7B-Chat,就要在「model」資料夾中建一個「Baichuan2-7B-Chat」子資料夾,並把git clone這邊的連結換成其他連結,例如https://huggingface.co/baichuan-inc/Baichuan2-7B-Chat。
下載及安裝過程中,一樣會要求輸入帳號、密碼以及相關驗證資料,而且一樣密碼跟驗證資料都不會顯示出來,這一部份要別注意,才不會出現錯誤。
「data」資料夾,裡面是要放置來訓練LLM的dataset(數據),例如你要訓練它產品相關資資訊,或是保固、客服相關回覆,都可以透過把寫好的資訊放在這邊進行處理。在技嘉官網的AI TOP Utility檔案裡,已經準備好一個寫好的「data」資料夾,裡面有兩個檔案,其中oaast_sft.json是已經預寫好的訓練用dataset,可以直接用在AI TOP的LLM訓練,建議第一次使用的人可以從這邊入手。
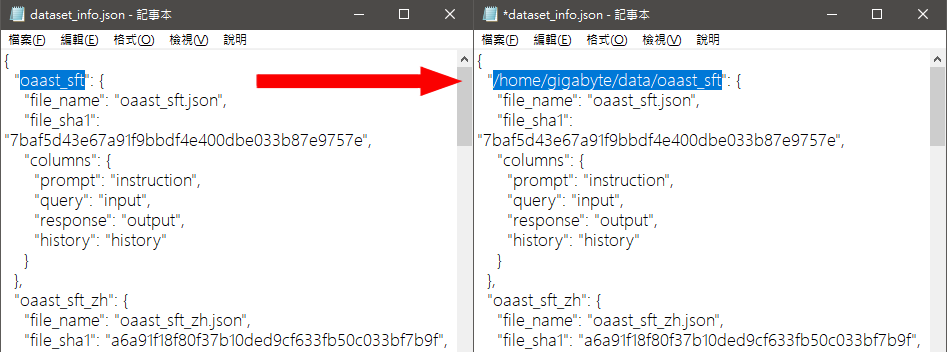
至於dataset_info.json這個檔案,需要稍微說明一下。因為我們要用oaast_sft.json這個dataset來訓練LLM 模型。所以需要有另一個檔案來註冊我們想要用來訓練的dataset(如oaast_sft.json),這個用來註冊的檔案就是data_info.json。實際的作法是用記事本編輯data_info.json ,並調整裡面oaast_sft.json 的路徑(如將/oaast_sft改成/home/gigabyte/data/oaast_sft)來進行註冊資料庫。這樣開始訓練的時候,系統才不會出現undefined dataset 的error 訊息。
調整完後,理論上就可以用oaast_sft.json這個dataset來進行LLM訓練。不過,如果您想挑戰自己撰寫dataset來訓練LLM 模型,這邊有一點要特別注意,每一個LLM對語言跟文字的支援程度不盡相同,所以dataset裡面要用哪一種語言來撰寫,要看LLM的支援程度,例如Llama 3 8B基本的中、英、日、俄,甚至西班牙文…等都沒問題,也就可以用更多的語言來撰寫,在撰寫之前可以先到官方網站或Huggingface 網站確認一下你要用的LLM的支援程度,這樣訓練會更順利。
最後的「output」資料夾則是用來存放訓練中的Check point資料及完成訓練後的模型,其中Check point主要是用來紀錄訓練階段資訊的接續點,以接續中斷的訓練,例如好不容易訓練進行到80%了,突然停電而失敗,有了這個Check point,就不用重頭跑一次流程,可以接續原本的進度進行下去,減少訓練的時間跟費用浪費,這個功能可以在開始LLM訓練後,在AI TOP應用程式裡啟用。
完成上面設定步驟之後,就可以到程式集開啟AI TOP 應用程式進行LLM訓練了,至於要怎麼調整AI TOP 應用程式的設定呢?下一篇文章告訴你。也請大家持續關注AORUS台灣社群網站:FB、IG、YT以獲得更多相關資訊。