自己的AI自己練-如何製作Dataset來最佳化你的AI?

對大語言模型來說,你需要使用它能解讀的”語言”來跟它溝通,這個東西就是Dataset。但是這個Dataset是一個程式檔,雖然,我們可以在hugging face網站下載到一些檔案,但是,這些資料是不是可以滿足每個人或是每個企業的特殊需求?應該大部分都不行,所以要自己寫。但又不是每個人都會寫程式,那怎麼辦?
沒關係,這次我們在新版的AI TOP應用程式裡加入Dataset編寫功能。只要準備好你要編寫的資料,不管是常用的純文字檔、Word檔或是Excel可以讀取的csv檔,甚至你在網路上取得,好像還蠻符合您需求的Dataset,它都可以調校並編寫成符合您需求,AI又可以識別的資料。
免寫程式 Dataset製作就這麼簡單
1.點選主畫面左邊的Dataset這個選項。
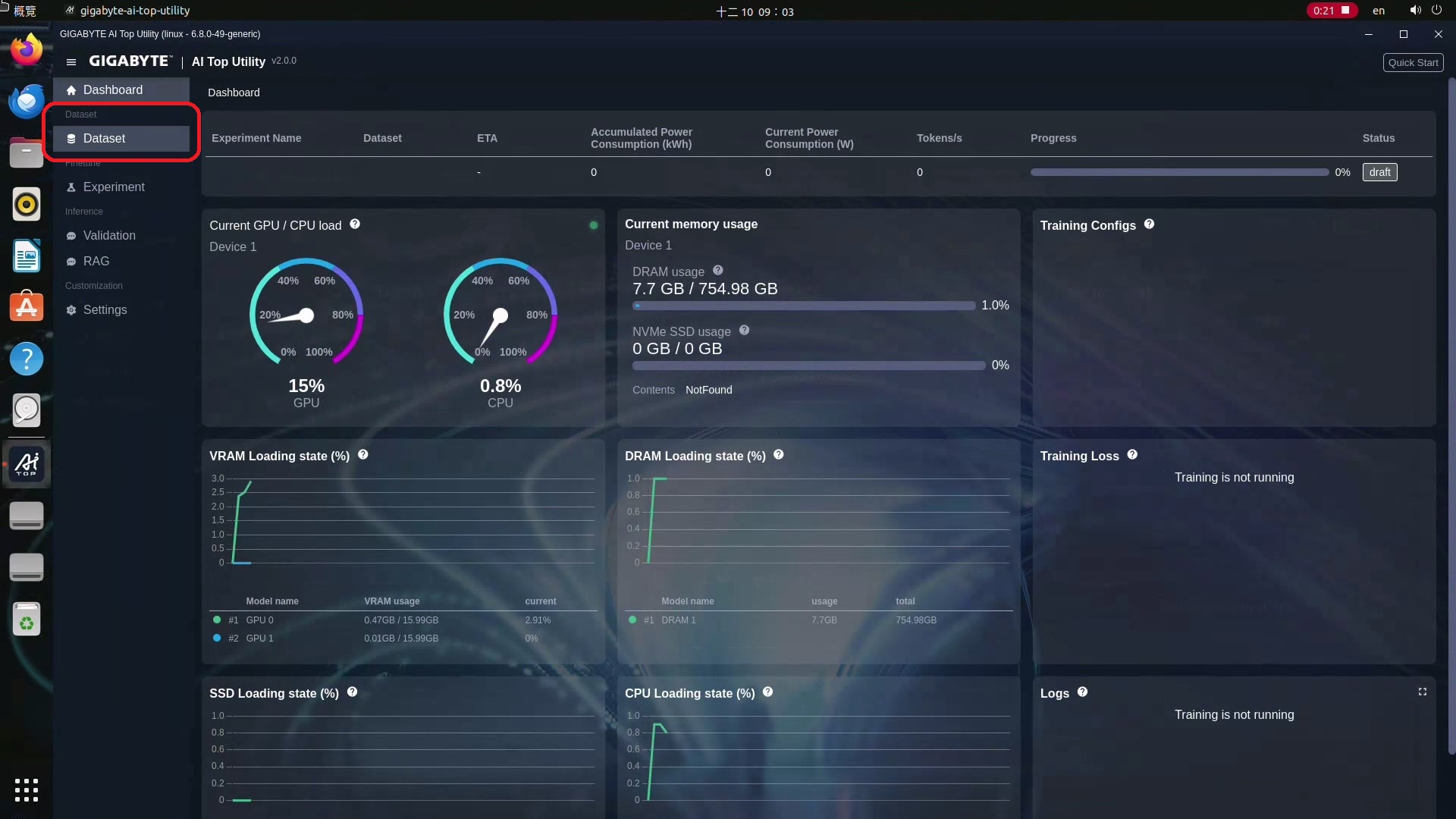
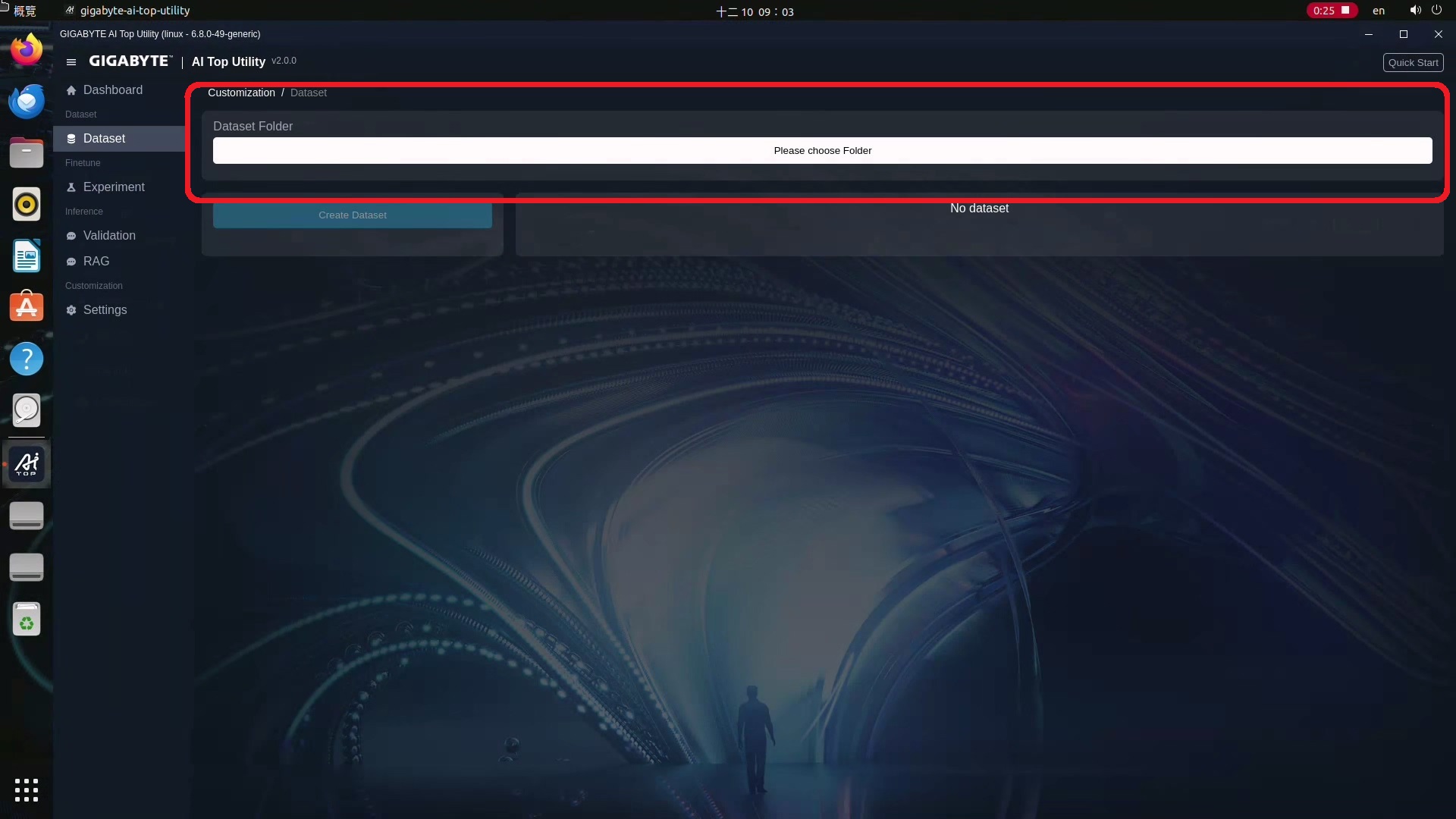
2.選擇你要存放Dataset的位置,這時系統會開始偵測,並會顯示現有的Dataset檔案及範本。
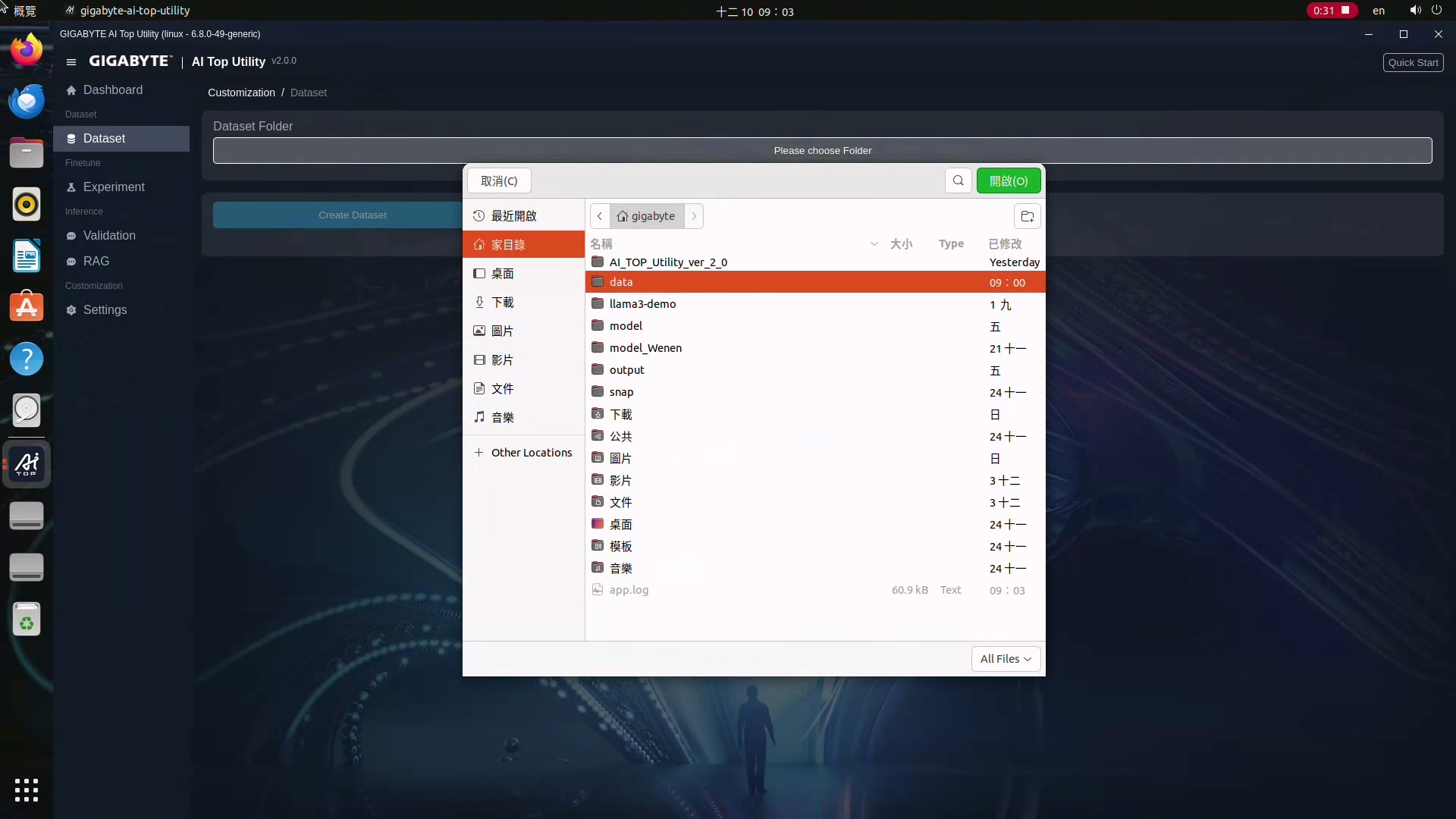
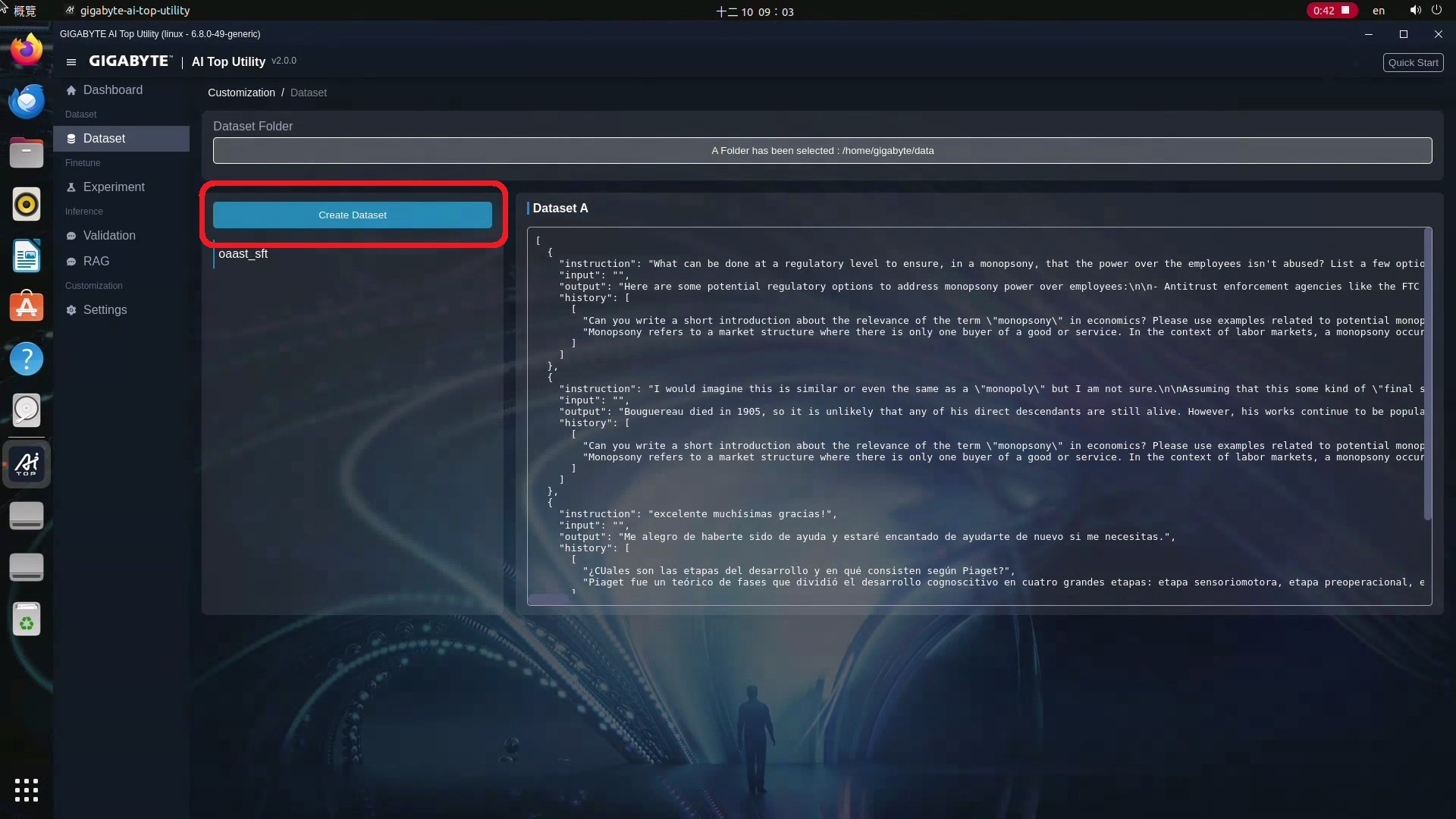
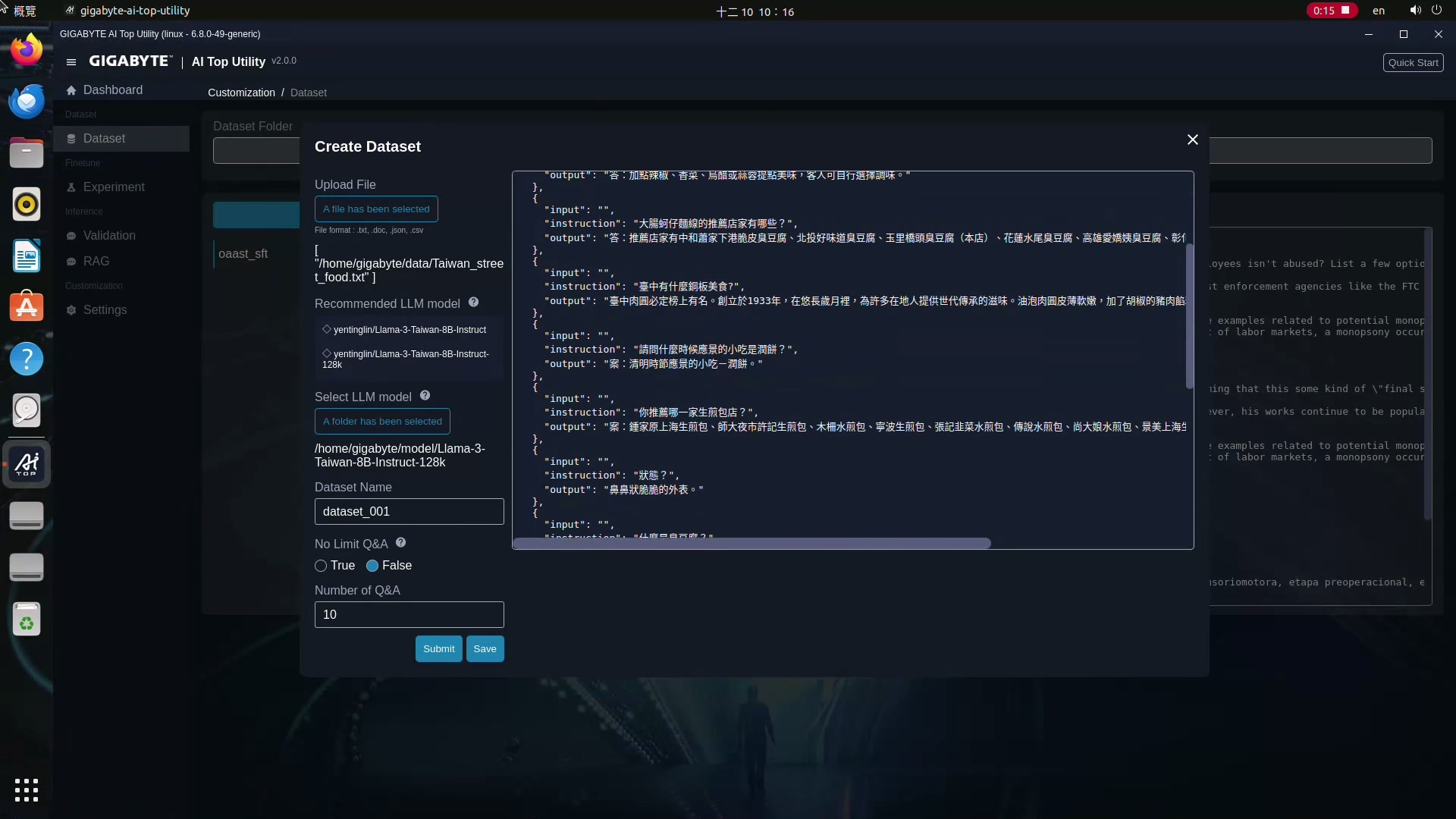
3.接下來選一下Create Dataset,會跳出一個彈出視窗,這邊要上傳事先準備,要做成Dataset的純文字檔或Word檔,同時,他也支援CSV以及.JSON檔案。
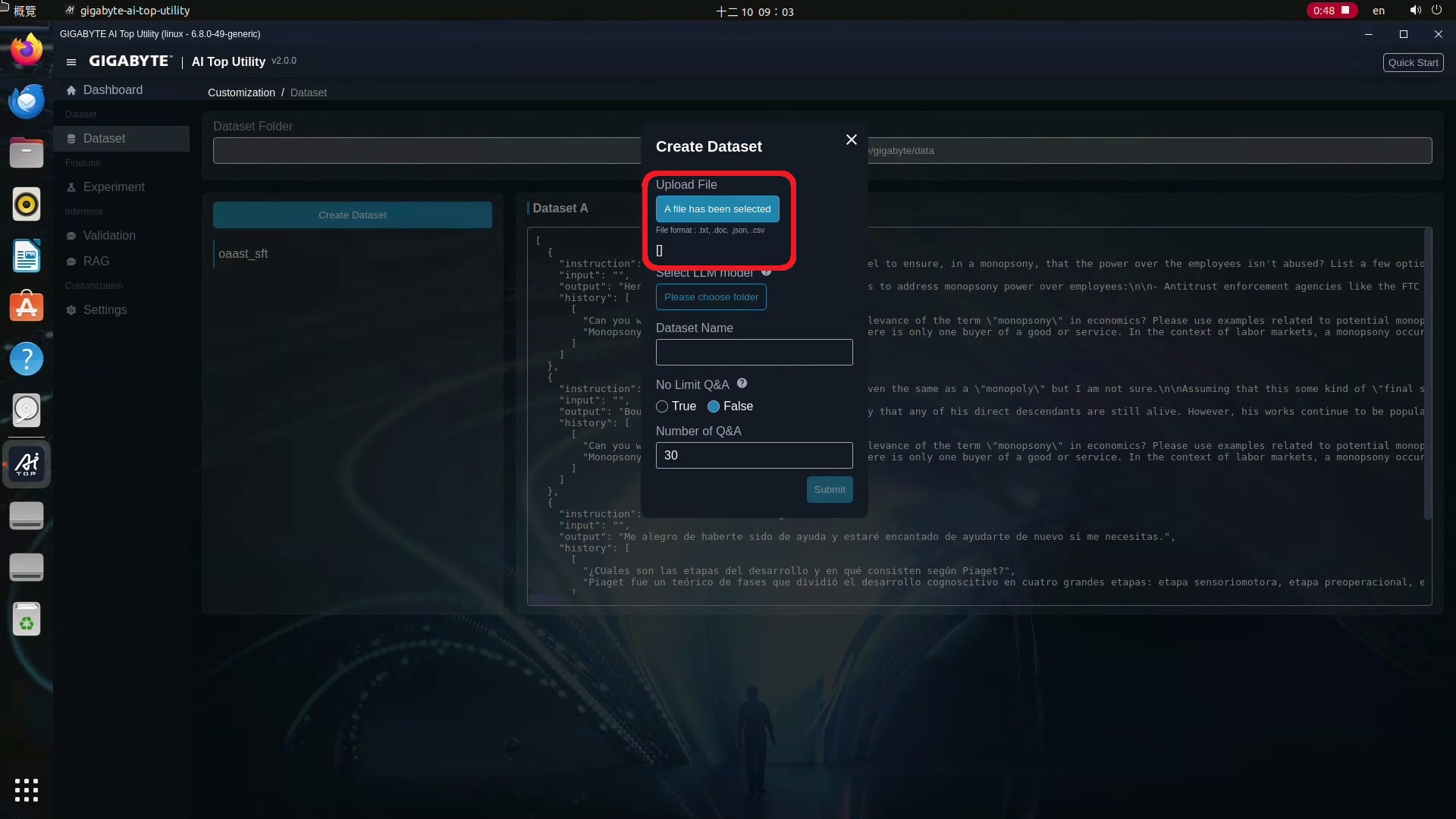
4.上傳後AI TOP會依照你上傳資料的語言別,顯示建議用來產生Dataset的大語言模型,以這邊上傳的中文檔案為例,他會建議繁體中文的模型,這樣可以編寫得更精準。
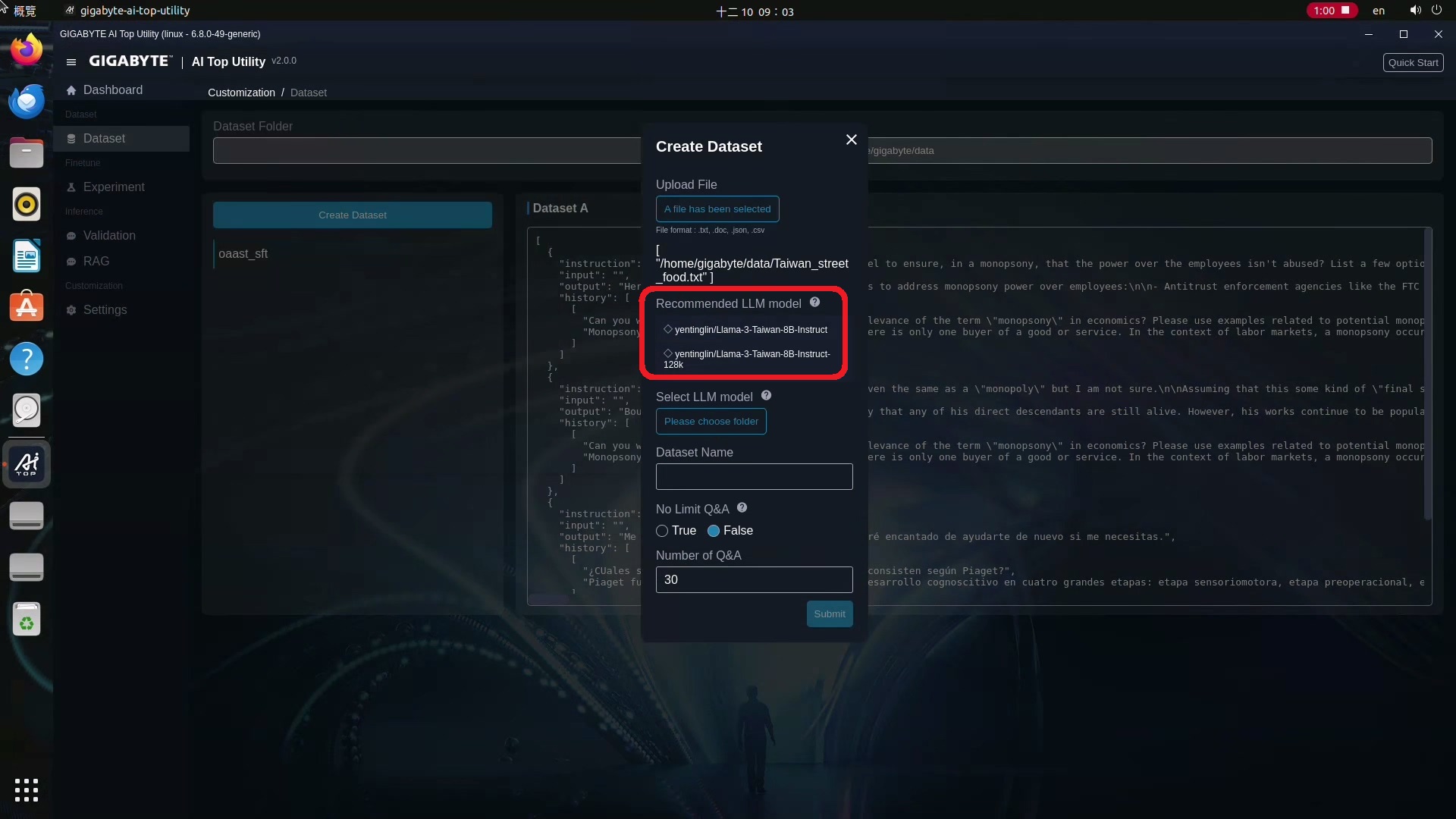
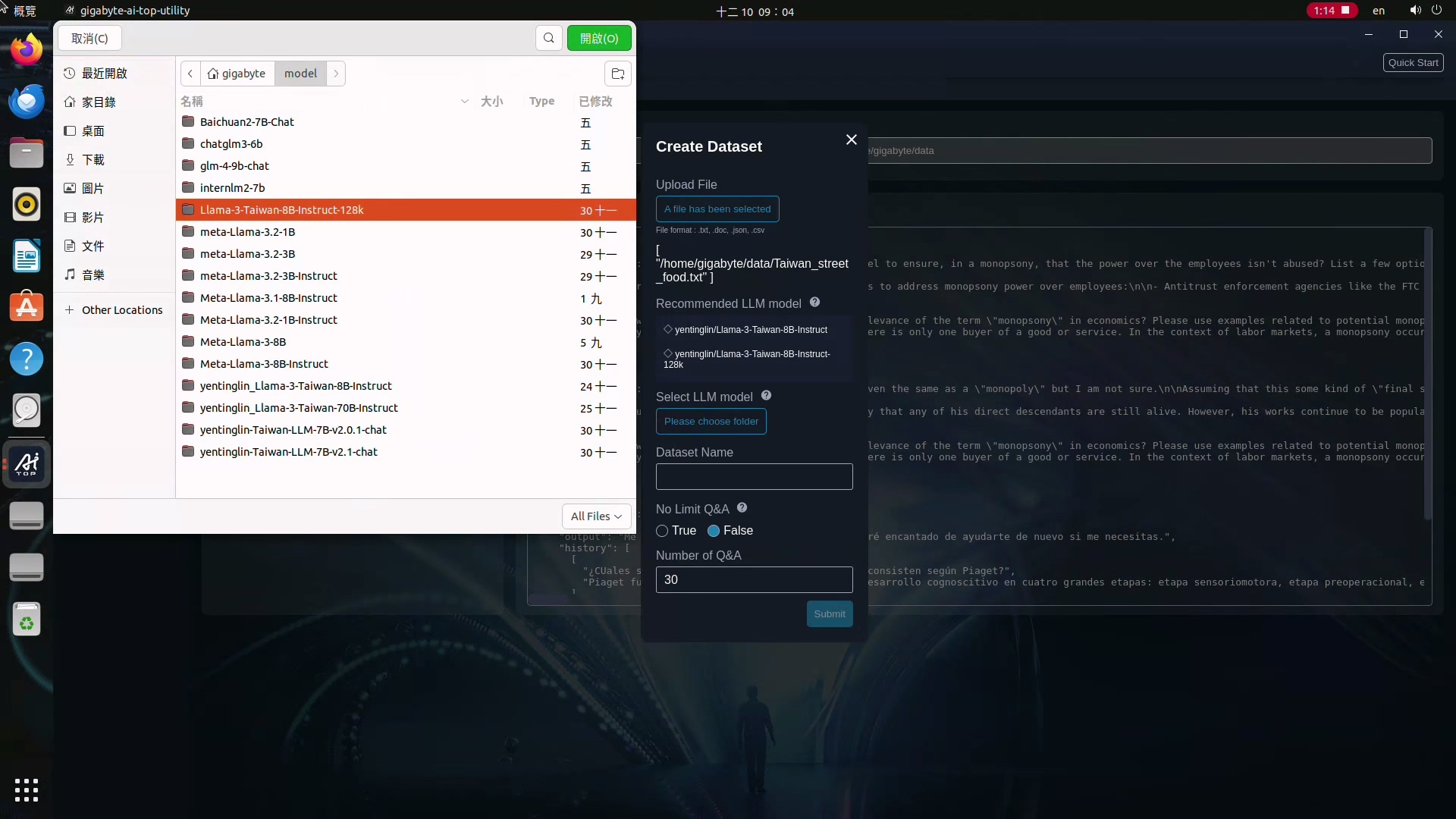
5.你可以依據建議,到Hugging Face這個網站下載建議的模型,並將 Select LLM model指向存放的資料夾。
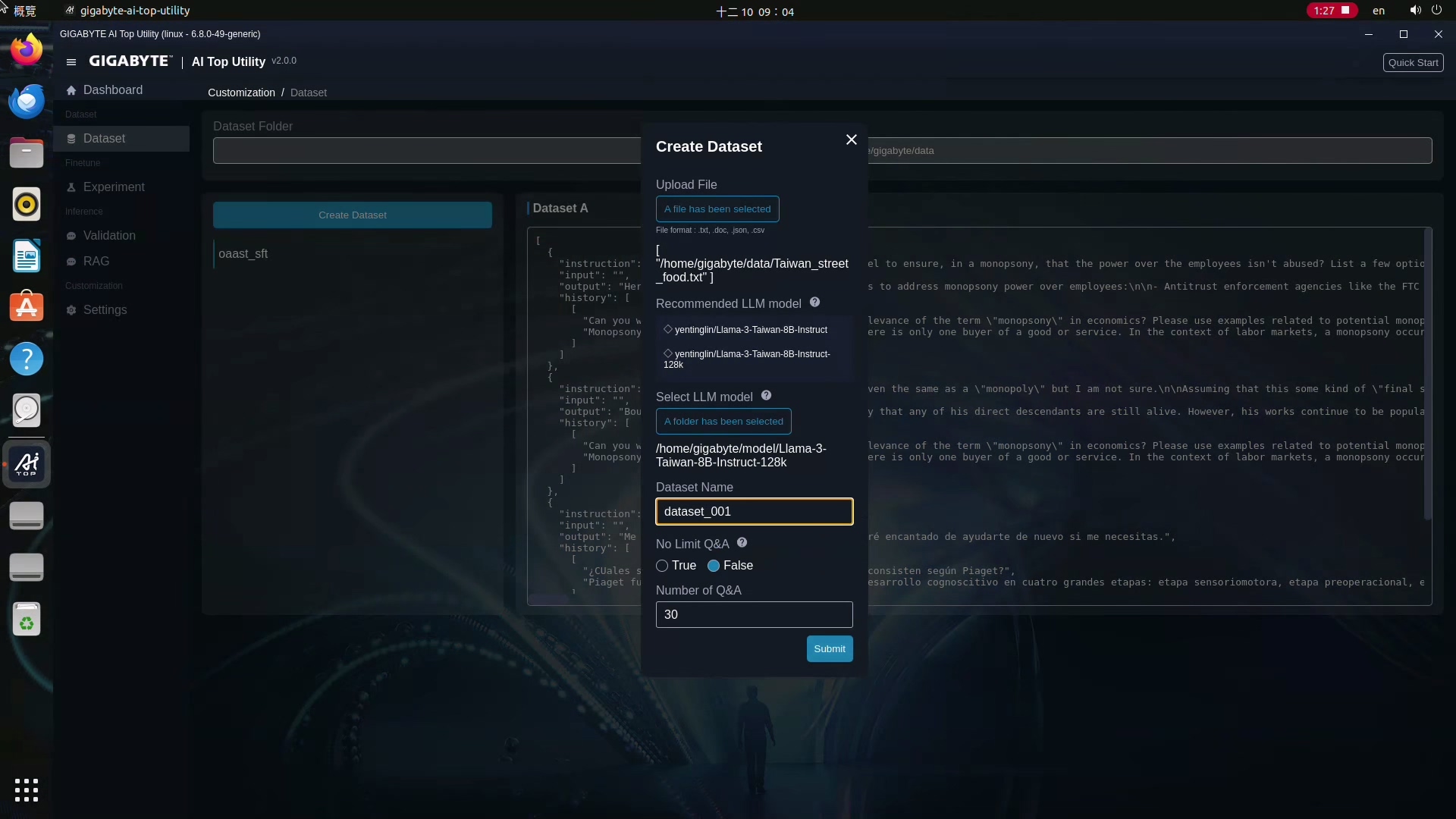
6.接著幫Dataset取個名字,最後設定你要它產出的問答數量,預設是30個,你也可以自己設定數量,或選擇產生無限制的問答讓它產生大概1萬個問答,等所有設定都完成之後,按下Summit鍵,接下來就等它製作。
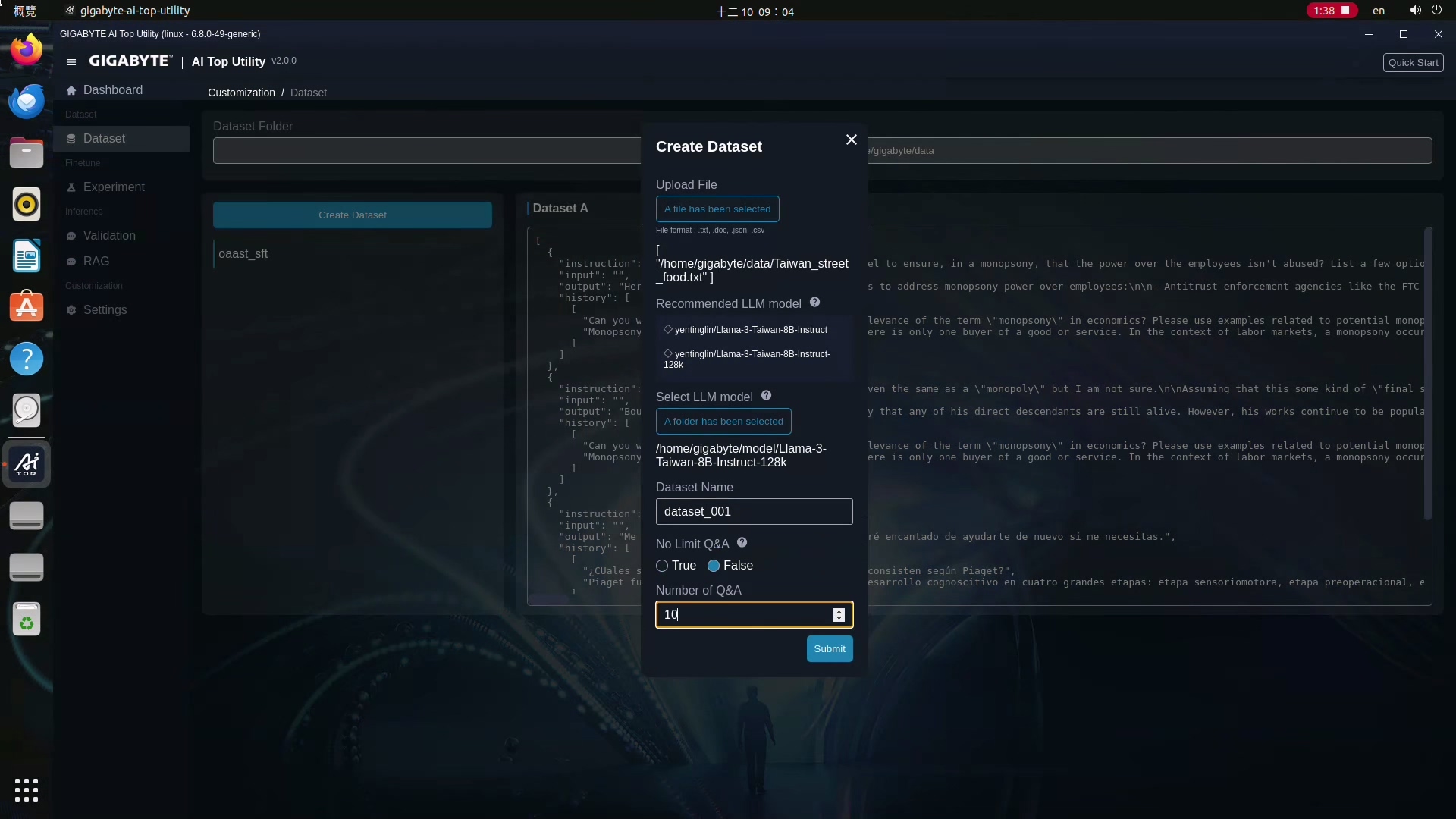
7.編寫所需的時間會依據你的原始檔案跟問答數而有所差異,所以如果你要產生的問題越多,就需要更長的等待時間,所以這邊先試試看10個。
8.等Dataset編寫成功之後,會顯示在畫面上讓你確認,如果想修改就讓他重新編寫,若是沒問題就按下儲存,這樣整個流程就完成。
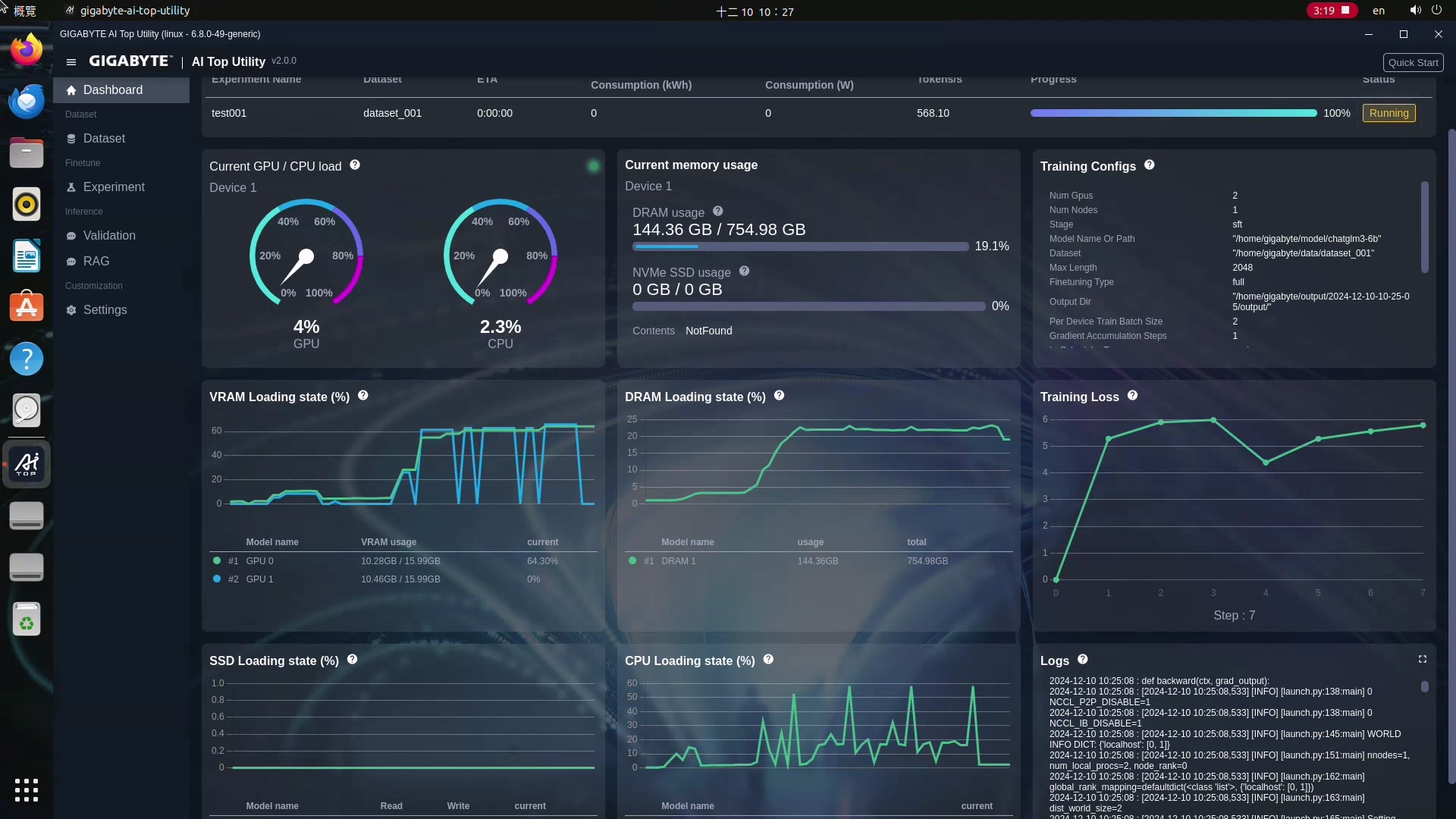
現在你可以開始用編寫好的Dataset來最佳化大語言模型了!
想進一步掌握最新資訊,請密切關注AORUS官方網站:https://www.gigabyte.com/tw/Consumer/Ai-Top/或AORUS台灣社群網站:FB、IG、YT
討論
- NEXT技嘉獨家連結技術:VisionLINK